GPU
The Llano chip GPU component, code-named "Sumo", incorporates many of the characteristics of the AMD "Redwood" GPUs family, which is implemented in the Radeon 5500 and Radeon 5600.

By comparing the two images, we see that not much has changed between "Sumo" and "Redwood" in the computing heart. We have the SIMD engines, 5 in total, each consisting of 16-thread processors and 4 texture units.
Each thread processor consists of a unit with a VLIW 5 architecture, capable of running up to 5 operations per clock cycle, giving a total of 400 calculations and of 20 texture operations per clock cycle. In addition there are two render back-ends, each capable of 4 raster operations (ROP) per cycle.
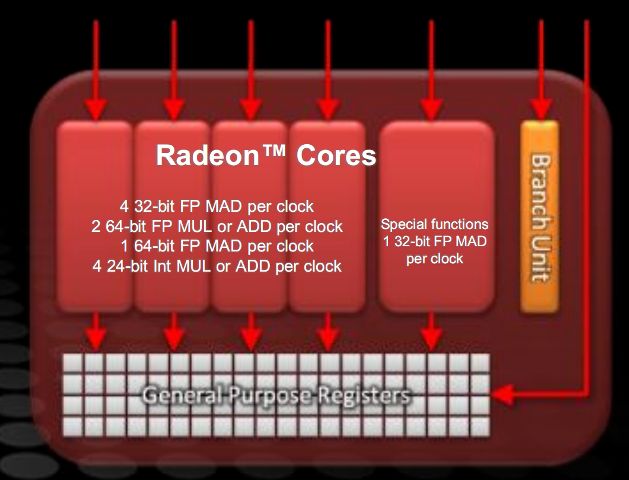
In particular, we can note in figure the structure of the VLIW 5 unit of AMD graphics architectures. The special functions unit can perform one floating point (FP) multiplication and addition (MAD) per cycle, or an execution step of a special function (such as transcendental functions, exponential, etc. ) per cycle.
The remaining 4 execution units can perform 4 32 bits FP MAD, or any combination of addition and multiplication of 2 64-bit FP, one 64-bit FP MAD or any combination of 4 24-bit integer addition and multiplication.
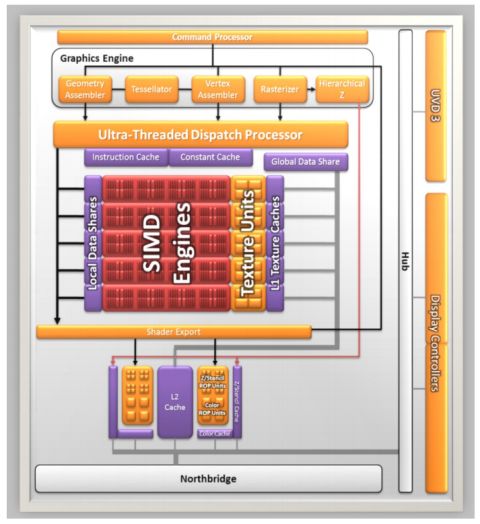
From the comparison with "Redwood", one can see that while the latter has a RAM controller for 128-bit DDR3 or GDDR5 memory, second generation UVD and 4 display controller, even capable of a certain level of Eyefinity technology support, "Sumo" has a direct connection to the 128-bit DDR3 RAM controller on the North Bridge, third-generation UVD and 2 controllers dedicated to the display. If you give up to have the PCI Express x16, you can configure other video outputs, to allow the implementation of the Eyefinity technology.
The integration of on-die GPU and direct connection to the North Bridge has helped the GPU, in part offsetting the fact that you have a DDR3 controller shared with the CPU.
The GPU is indeed connected to the rest of the system by well 3 BUS.
The first link is the "Garlic", which is a direct connection, without coherency check, low latency, 128-bit, between the GPU and RAM controller, arbitrated by the sole RAM controller front-end, which ensures high-priority and low latency. The frequency at which such a link operates would presumably be that of the Northbridge, which should be around 2 GHz, since AMD says it has a bandwidth of more than 30GB/s to the RAM controller, while 2 billion transfers per second is slightly over. It's an improvement over the 64-bit bus for the Ontario/Zacate GPU.
The second link is the "Onion", which interfaces the GPU with the coherent system, composed by the memory, the CPUs and their caches, which is ruled by the MOESI protocol. This direct and low latency connection is a significant step forward. With an external GPU, especially with an IGP, you had to go through the bus connection between the graphics card (or the North Bridge in the case of IGP) and CPU, to wait for its integrated North Bridge controlled the cache and eventually RAM and send the results back. Now the two checks can be done independently and in parallel (through both Onion and Garlic interfaces) and with a much lower latency.
The third connection is the one direct between the GPU and the GIO unit, for access to the PCI Express controller, for an eventual CrossFire with discrete card and video outputs management. The same fate is not up to the cores of the CPU that, to access the GIO, shall pass through the North Bridge and suffer the latencies and waiting.
Another great advantage of an integrated GPU on the same CPU chip is related to the exchange of data in memory. With conventional graphics cards, to render a scene, several data structures must be used: grids of vertices (mesh), color and lighting information and texture mapping for the final color.
These information are created from the 3D software into memory and are passed to the graphics card driver. Because the processes are working with virtual memory, to access them, the driver may even need to load it from disk. In any case they should be transferred to the internal memory of the video card via the PCI Express bus.
Similarly happens for GPGPU calculations, where, in addition, the data must travel even the reverse the route, to load into main memory the calculation results.
All this with an APU is no longer necessary. The Llano APU implements 2 techniques to speed up these operations.
The first is called zero copy, and allows you to not copy the data anymore, but simply to say where they are to the GPU and they may be used directly. This is possible because the GPU can directly access the RAM. But the virtual memory moves data in and out of memory and re allocate it at will. Llano does not yet implement a sophisticated virtual memory manager to help you get an unified memory space. The next architecture will implement it and make the GPU a real vector coprocessor, similarly to first FPU appeared years ago.
To avoid problems, the second technology is employed: Pin in Place. This is to block data structures in a specific area of memory, so the GPU can find and access them safely and they are not to be taken out of memory, on hard disk, extending access times.
When virtual memory will be implemented in future generations of GPU in a manner identical to that of the x86 CPU, then you can talk about unified memory space and such software tricks will no longer be necessary. It would even be possible to page out to disk graphics memory, if they implement the exchange of page fault signals from the GPU to the CPU.
These technologies let, in exceptional cases, have a greater speed than that of a discrete video card. But the sharing of the RAM controller, however, makes the GPU a bit slower than its discrete equivalent.
The GPU, unlike the one implemented in Sandy Bridge, fully supports DirectX 11 and angle independent anisotropic filtering.
Other features supported are OpenGL 4.1, OpenCL 1.1 and MSAA, SSAA and MLAA anti-aliasing techniques.
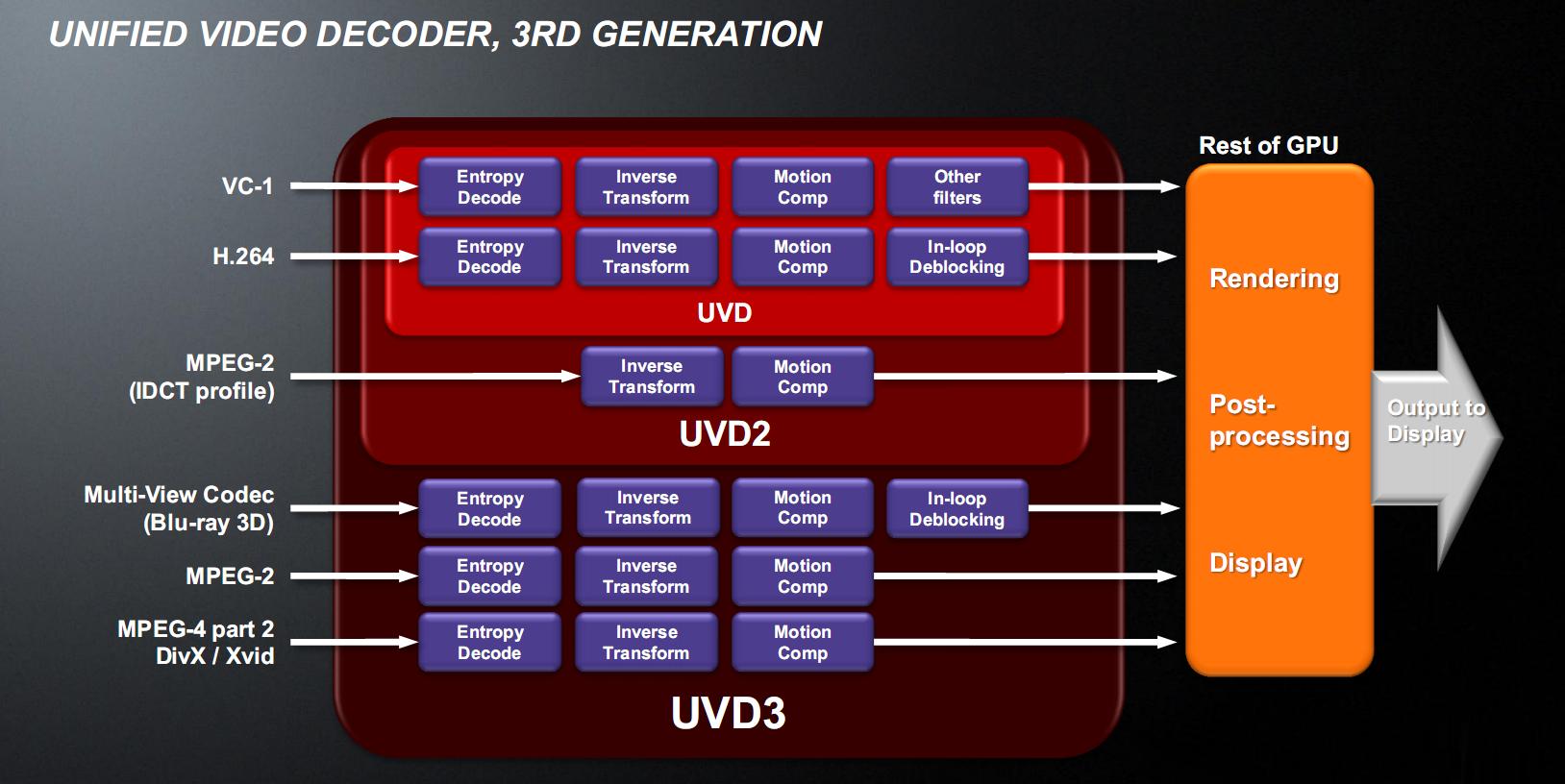
In the picture you can see a block diagram of the various generations of UVD. The third generation, implemented in Llano, can hardware accelerate the MPEG-4 Part 2 (which also includes the DivX and Xvid), MPEG-2 codec and Multi-View Codec (MVC) used to accelerate Blu-ray 3D, which can be viewed through the HDMI 1.4a port which Llano has.
The decoding is all done in the UVD3 block, so the rest of the GPU can be placed in advanced energy-saving (power gating) and save a lot of energy.
Dual Graphics
Last chapter for the GPU is Llano Dual Graphics technology. It allows you to pair, like CrossFire technology, video cards to increase performance. But unlike the latter, it can balance the load between the GPU, taking into account the differences in power.
The mechanism is not perfect, since it is greatly affected by the quality and maturity of the drivers and also works well with DirectX 10 and 11. With DirectX 9, the performance are equal to those of the slower card.
As we saw earlier, CrossFire/DualGraphics and Eyefinity technology are mutually exclusive unless you settle for a smaller number of display interfaces: the x16 PCI Express controller can be divided into two x8 controllers, one of which can be used for CrossFire and one for additional displays. Of course to get the maximum number of video interfaces is necessary to give up to CrossFire support, so as to obtain a full CrossFire support, with x16 interface or two x8 interfaces, to perform a triple CrossFire is necessary to give up to Eyefinity support.
In the event that the performance difference between the discrete card or cards combined with the GPU will be high, the performance increase over discrete card usage only is fairly modest.
In compensation, however, AMD has implemented the drivers so you can route OpenCL 1.1 calls to the integrated GPU without impairing the discrete GPUs, if they are working on a heavy 3D load.
